Résultats
Performances
sur 5 aéroports.
Évalués sur un test set d'alertes complètes jamais vues à l'entraînement (GroupShuffleSplit, 20%).
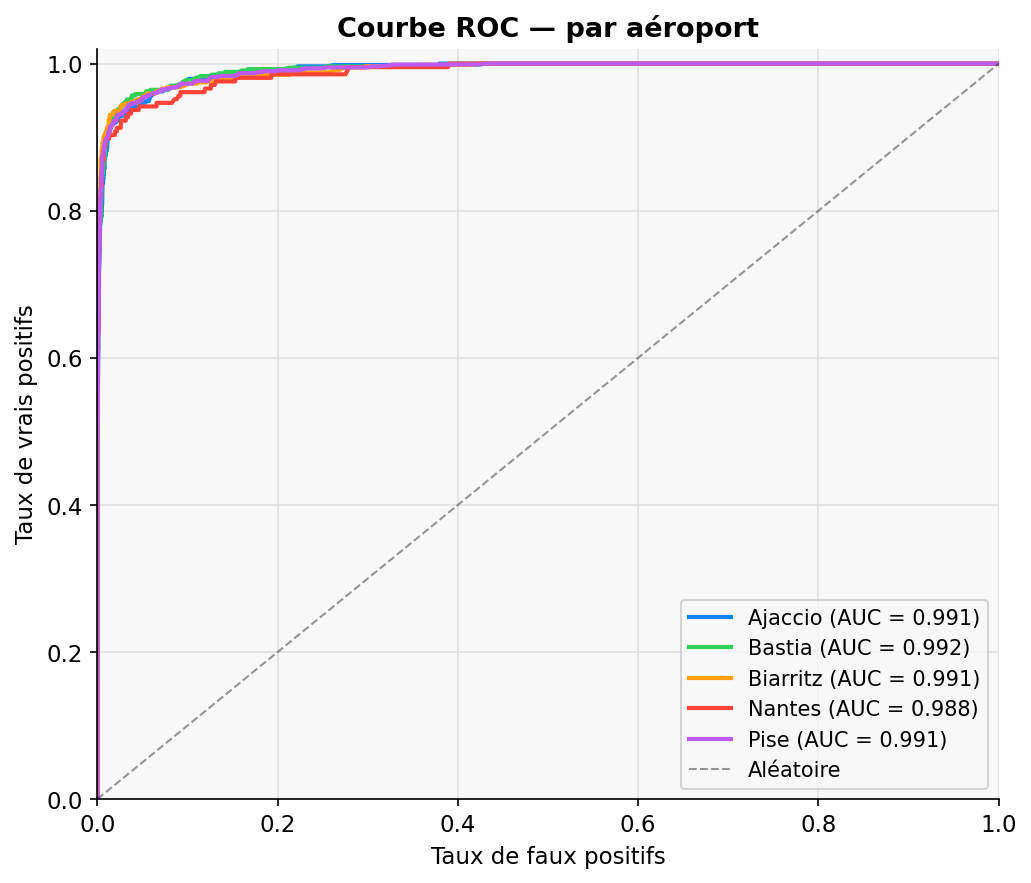
AUC-ROC global
0.966
Discrimination parfaite = 1.0. Mesuré sur alertes non vues à l'entraînement.
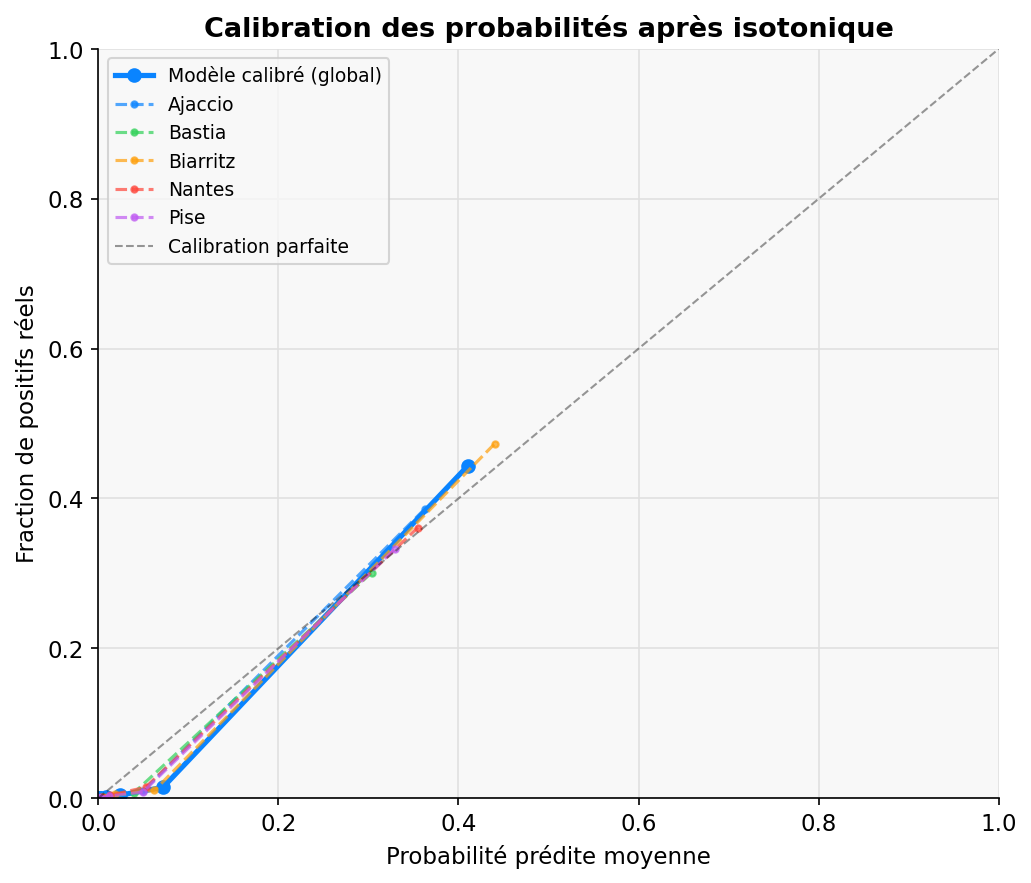
Brier Score
0.018
Calibration des probabilités. 0.0 = parfait. Après isotonic calibration.
Gain total
150h
Gain cumulé sur toutes les alertes d'entraînement à θ=0.4 vs baseline 30 min.
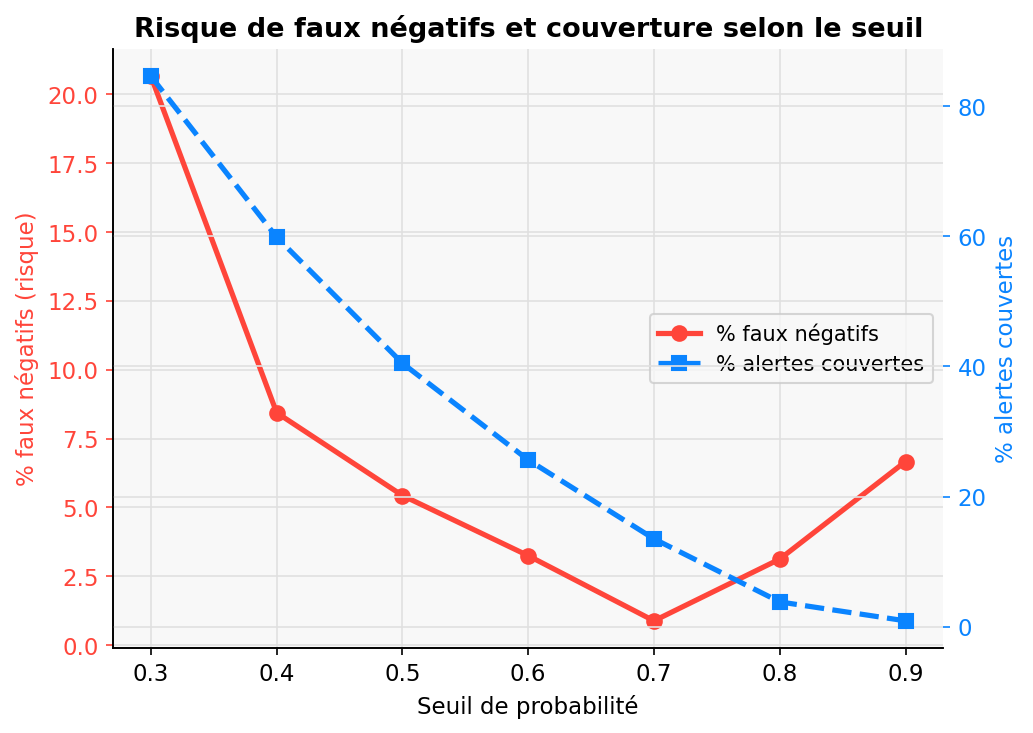
Risque R à θ=0.4
1.80%
Fraction d'éclairs <3km ratés. Seuil acceptable : R < 2% (protocole Meteorage).
Courbe ROC — par aéroport
Calibration des probabilités
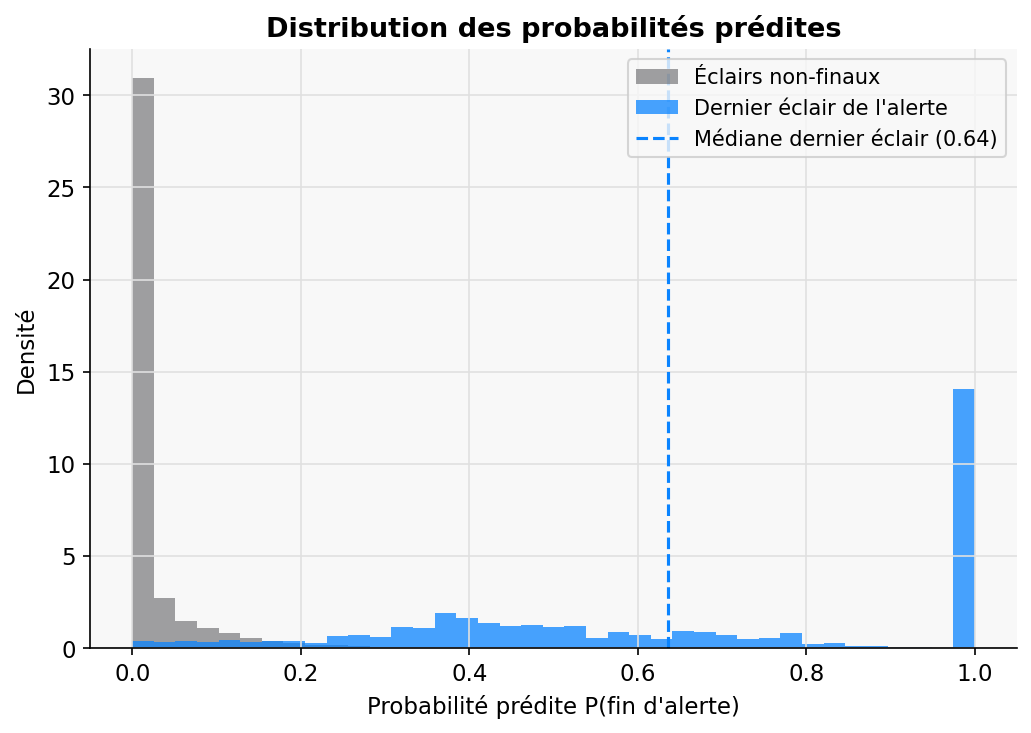
Distribution des probabilités prédites
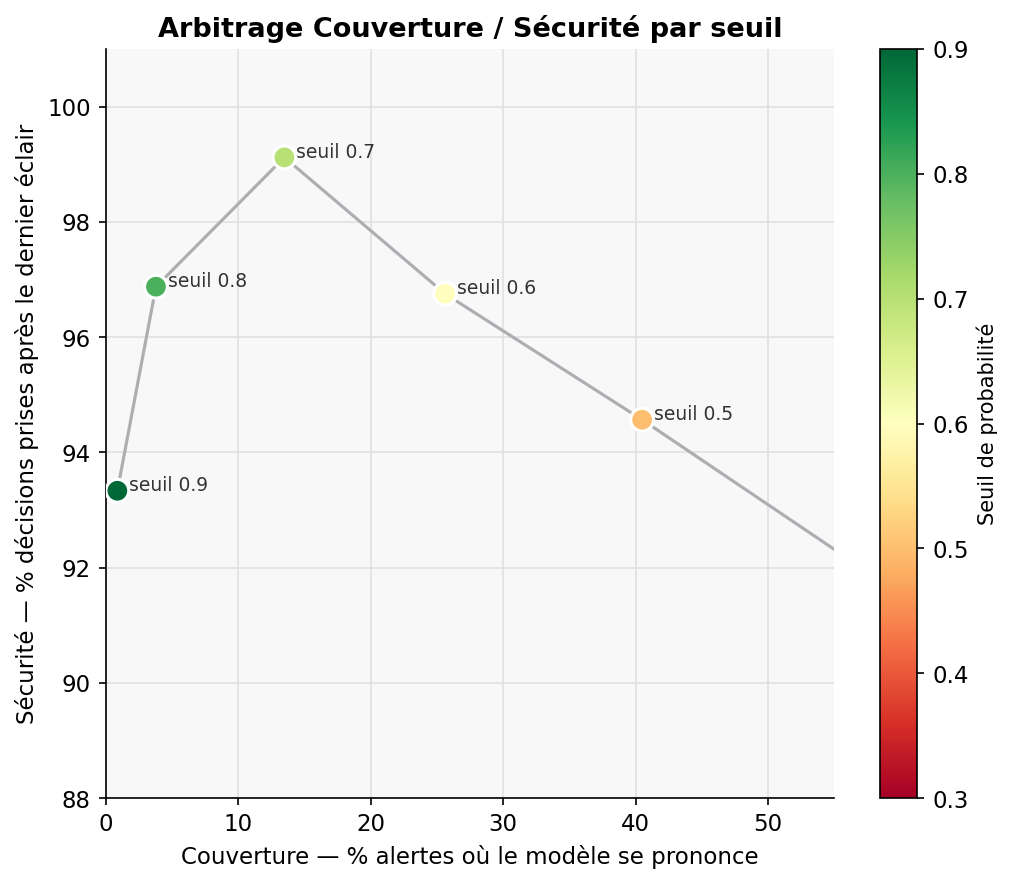
Arbitrage couverture / sécurité